提升语音交互体验——让AI更懂你
“Hi,Siri,今天天气怎么样?”
“小安,你好,导航去虹桥国际机场。”
“小爱小爱,关闭灯光。”
人工智能似乎已经成为了当下科技的最热趋势,无论是智能汽车还是智能家居,受欢迎的根本都来源于其高度的可交互性和可操作性。人类在许多自然场景或商务场景中,添加了相应的智能组件来减少不必要的工作量,提高工作效率和生活质量。例如用语音控制车机改变车内空调温度、导航目标地点,用语音总控智能家居的各项开关等等……

然而,人机交互模式中,一方面受限于机器端自动语音识别的准确率——环境噪声、说话人相对于麦克风的位置以及交替谈话场景等因素都会影响自动语音识别系统接收到的信号,一方面又受限于人体端发音的清晰度和语言差别,繁杂的变量导致最后所呈现的交互效果各不相同,难以精准复现。
为了再现含有多种测试变量的声学场景,HEAD acoustics专门开发了VoCAS(语音控制分析系统)软件。即使在复杂场景中,也能真实客观地评估集成了语音识别功能的设备对信号的预处理效果。这种预处理可以在信号发送到实际语音识别系统之前,“清除”所有潜在干扰和有害伪影--无论该功能是在云端还是在本地设备或本地服务器上实现。
通过 VoCAS,工程师可以自由构思和规划ASR系统相关的自动化测试。VoCAS软件能够追踪所有因素,如背景噪声、混响、不同的语言和口音,以及不同的、甚至是多个交替说话的谈话者,并轻松地组合和变更这些因素,将其改变为复杂程度各异的测试和分析。
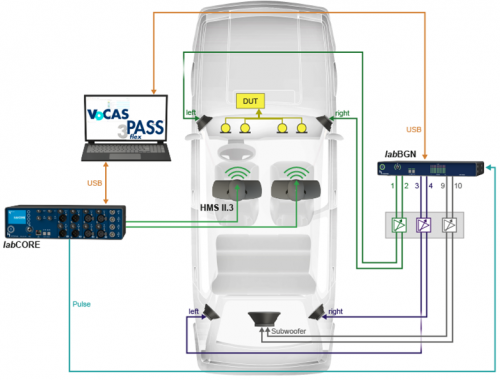
当然,为了保证精准复现交互场景,VoCAS联动了3PASS flex、3PASS lab、HAE-BGN、HAE-car,甚至是3PASS reverb混响模拟等噪声还原系统,营造出最自然的声学环境:例如在移动的车辆中进行对话,在嘈杂的自助餐厅中唤醒手机内的语音助手,在车水马龙的街道上语音搜索导航路线等等。
既需要还原噪声场景和交互语音,又要从ASR设备中获取预处理信号,这样高度专业化的分析软件使用起来却远比想象中简单许多。VoCAS软件简化了大量繁琐步骤和算法,仅使用标签就能快速方便地管理大量语音指令的文件,直观地为任何语音识别系统创建自动测试序列,同时也可以在集成的录音程序上录制自己的语音指令,或导入现有音频数据——轻松剪切和过滤文件,并将其校准到指定的语音电平。
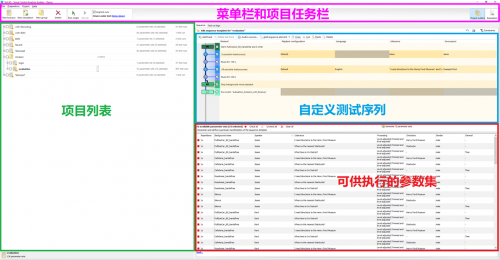
除此以外,VoCAS软件本身支持Python脚本定制语音识别系统定制和自动化测试序列。使用脚本完成触发对应得噪声、检测TTS(text-to-speech)反馈、接收串口指令、评估测试结果等复杂操作,将测试内容一键化,让测试更加专业高效。
VoCAS 带来无限可能。点击图片,发掘 VoCAS 更多功能。

https://www.head-acoustics.cn/products/analysis-software/telecommunication-and-audio/vocas
标签:





